CoreWeave Achieves #1 Ranking for Inference Speed and Price-Performance for Moonshot AI’s Kimi K2.6 Model in Independent Benchmark
Key Terms
serverless inference technical
dedicated inference technical
kubernetes technical
quantization technical
speculative decoding technical
mlperf technical
agentic technical
Full stack optimization across memory architecture, runtime, and interconnect translates into the speed and economics enterprises need to run open-source AI in production
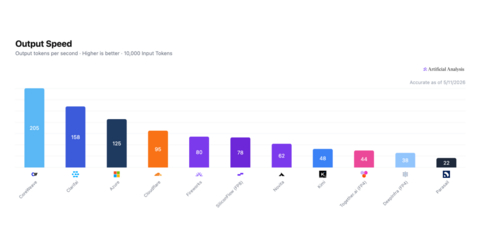
CoreWeave ranked first in the most attractive quadrant for inference speed and price-performance on Kimi K2.6, as independently measured by Artificial Analysis.
As AI applications move from training into production, inference efficiency increasingly determines real-world product viability. For organizations running the full AI loop from training to inference to continuous improvement, throughput, latency, and cost per request directly shape how reliably and economically AI can scale in the real world. This is especially significant where performance is non-negotiable, like coding assistants, agentic systems, and real-time enterprise copilots.
“Training launched the first wave of AI, and inference will define the next one. That’s why the effectiveness and economics of inference are becoming critical to organizations bringing AI into the products people use every day,” said Chen Goldberg, Executive Vice President of Product and Engineering at CoreWeave. “This benchmark reflects the investments we’ve made across our full stack, and the deep expertise of CoreWeave engineers in optimizing performance and efficiency. This is a clear signal that speed, responsiveness, and predictable economics are attainable for customers today.”
"Performance gains in inference systems come from optimization across the full stack, including hardware, inference runtime, and model configuration,” said George Cameron, Co-founder at Artificial Analysis. “Artificial Analysis benchmarks are intended to give organizations transparency in how inference offerings perform. CoreWeave performed strongly across speed and price-performance dimensions in our benchmarking of providers of Kimi K2.6. For those deploying agents in production, inference speed and price are critical to user experience and to making open source models a viable choice at scale."
The gap between theoretical compute capacity and actual production throughput is influenced by how well hardware, model optimization, and runtime execution are tuned together. CoreWeave has optimized its platform across all three layers.
The benchmark result, as validated by Artificial Analysis, reflects the company's investment in full stack infrastructure optimization for production AI workloads. CoreWeave Inference and Applied Training teams achieved top speed by training an in-house NVFP4 Quantization with Eagle3 Speculative decoding on NVIDIA GB300 NVL72 hardware delivering 205 token/sec at
- Serverless Inference, which provides immediate API access to optimized models with no infrastructure to manage.
- Dedicated Inference, which provides a predictable path to production with explicit control over the number of GPUs for the required scale, while all inference services are still managed by CoreWeave.
- Inference on CoreWeave Kubernetes Service (CKS), which means developers can work with direct, bare-metal access to AI infrastructure, allowing for deep control over the entire stack.
Artificial Analysis is an independent platform that benchmarks and analyzes AI models, API providers, and infrastructure. It provides data on model quality, speed, cost, and reliability, helping users (developers/enterprises) compare and select AI technologies. Artificial Analysis independently benchmarked Moonshot AI’s Kimi K2.6 by testing its performance across 10+ core metrics – including MMLU-Pro, GPQA, and agentic coding tasks –to evaluate speed, cost, and reasoning capability.
The Artificial Analysis result is the latest in a series of independent validations of CoreWeave. The company is the only AI cloud to earn the top Platinum ranking in both SemiAnalysis ClusterMAX™ 1.0 and 2.0, which evaluate AI cloud performance, efficiency, and reliability, and also demonstrated record-breaking MLPerf® benchmark results.
Learn more about CoreWeave’s recognition on our blog or on Artificial Analysis’s website.
1Price performance is measured in Speed vs. Price
About CoreWeave
CoreWeave is The Essential Cloud for AI™. Built for pioneers by pioneers, CoreWeave delivers a platform of technology, tools, and teams that enables innovators to move at the pace of innovation, building and scaling AI with confidence. Trusted by leading AI labs, startups, and global enterprises, CoreWeave serves as a force multiplier by combining superior infrastructure performance with deep technical expertise to accelerate breakthroughs. Established in 2017, CoreWeave completed its public listing on Nasdaq (CRWV) in March 2025. Learn more at www.coreweave.com.
View source version on businesswire.com: https://www.businesswire.com/news/home/20260511094399/en/
Source: CoreWeave, Inc.